A few weeks ago LinkedIn quietly updated its privacy policy to inform us that they are now using our personal data, articles, and likely every "congrats on the new role!" bland comment to train their own AI models.
"On November 3, 2025, we started to use some data from members in these regions to train content-generating AI models that enhance your experience and better connect our members to opportunities."
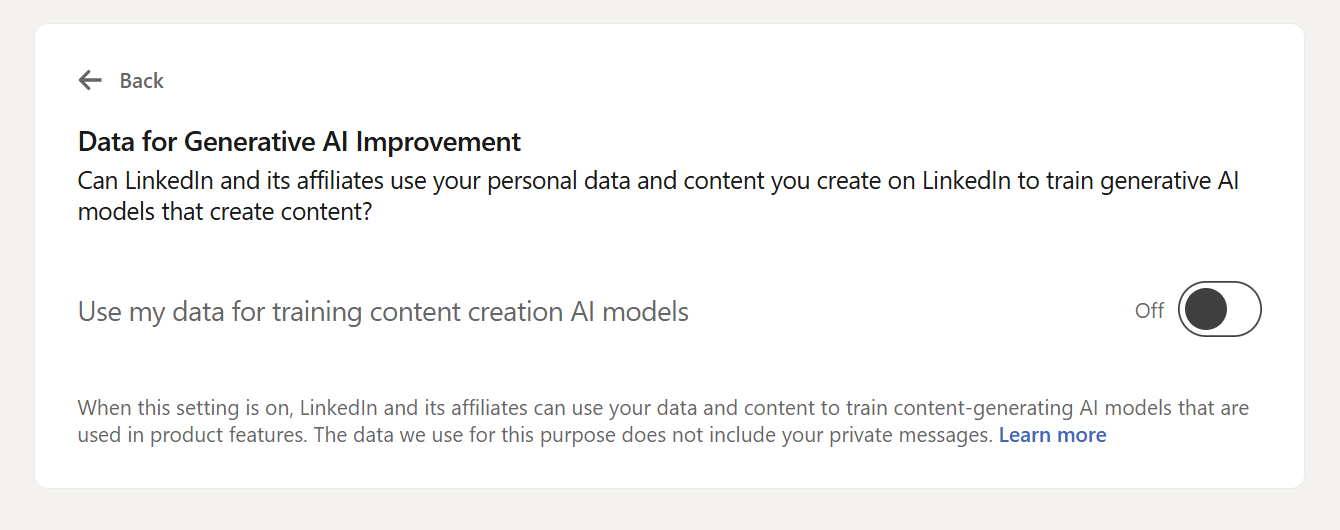
If you are also not especially overjoyed by the news, you can turn it off. Go to Settings & Privacy > Data Privacy > Data for Generative AI Improvement and toggle that switch to "Off."
But this announcement gave me an idea.
I was wondering what exactly Ryan Roslansky, CEO of LinkedIn, is going to do with all our collective data. Like many people I have a love/hate relationship with LinkedIn, or put more precisely: tolerate/hate. The obsequious veneer of performative success and self-congratulatory promotion that defines the platform is decidedly "mid," IMHO. This occasionally leads me to write posts that simply tell the truth or slightly poke fun at it all, but let's face it; I'm on there like everyone else because I'm distracted, bored, and I have some vague notion that it will help my career. What infuriates me is that I have actually made excellent connections, built friendships, and furthered my career all from LinkedIn. However, it's hard to see how the introduction of whatever LinkedIn's AI boffins can cook up would make the world's most unlikely social network's vibe actually any worse than it already is.
My LinkedIn Data
So I was thinking. If a massive corporation is mining my sardonic thoughts to train their AI, why shouldn't I use my own LinkedIn data to train my own AI model?
The posts that we all put out on various social networks are not our true selves; they're a carefully, or in some cases, not so carefully, manufactured facet of what we put out into the world. Now I'm not the most prolific online poster, but I wondered if I had enough posts to train an ML model on what I was putting out on LinkedIn, then what would it be like to interact with that model, to talk to it and have it talk back in my contrived LinkedIn voice?
It's a concept straight out of Black Mirror's 2013 "Be Right Back" where a grieving widow reconstructs her boyfriend from his online history placed in an android body. If you've not seen the episode: spoiler, things did not turn out well. Over a decade later we have off-the-shelf ML cloud services that can do much of what is explored in that episode. Apart from human-realistic android robots; the best we can come up with there is slick consumer marketing and mannequin human control for anything as difficult as "opening a door".
To create this simulacrum of my corporate persona I first need the data. Also I can't afford a datacenter full of high-end NVIDIA GPUs, so this is going to require some serious corners to be cut to keep this affordable. This has to be cheap, scrappy, but feeding in a huge prompt into Chat-GPT or Gemini isn't really going to cut it either as I'm really trying to train a model to become me, not just force feed a prompt with data into a giant LLM. Ideally we can do more with my LinkedIn model once it's up and running. Can it remember? Can it learn? Can it actually be useful for something? Would this be the one AGI that finally escapes the lab and becomes self-aware in a world-ending SkyNet event? If so will it post pithy memes while it enslaves humanity? I sure do hope it loves to troll, but I'm getting ahead of myself, and I've not built any of that yet.
So this is the story of how I built it. Or rather, how I started to build it, immediately hit a data engineering wall, and then engineered my way over it using synthetic data generation.
Welcome to Part 1: The Data Harvest.
LinkedIn Digital Sludge
Getting the raw data is actually the easy part. LinkedIn provides a tool to download your data archive. You request it and then annoyingly have to wait 24 hours, at which point they send you an email with a link back to the site where you can finally download a zip file of all the content LinkedIn has ascribed to you. Inside, buried among a hundred other files, is Shares.csv, containing every post, reshare, and link you've ever subjected your network to.
Example line from my Shares.csv file:
""Also why does LinkedIn have a ""Rewrite with AI"" option? Do I want to get this post turned into vapid platitudes devoid of any personality? Not a use case I'm interested in and I cant wait for 24 months time when all these ridiculous features are pulled without fanfare from every product we use as they must have AI because reasons.","","",MEMBER_NETWORK
The ShareCommentary column, which contains the actual text of your posts, is not a clean string. Multi-paragraph posts are broken up by escaped quotation marks and newlines, scattered across multiple rows. The URLs you shared are in a completely different column (SharedUrl), disconnected from the commentary. Reshares of other people's content are indistinguishable from your own original thoughts. This is less of a dataset and more of a data sludge. Feeding this hot garbage into a language model wouldn't produce an insightful clone; it would produce a broken spambot that regurgitates fragments of half-remembered networking pleasantries.
We have data, but we need clean data. More importantly, we need structured data. The raw material isn't just messy; it's in the wrong shape entirely.
Choosing the Model to Train
If you're not familiar, training an ML model alters it permanently. This is totally different from Uploading a .csv file to ChatGPT and asking it about the contents. The Big LLMs like Claude, ChatGPT and Gemini have trillions of parameters, and they are stateless. That means they can't remember anything between uses. To get around this, these systems re-prompt the model with snippets of earlier conversations each time you interact, or use methods like RAG (Retrieval-Augmented Generation) to effectively force in data to that stateless model when you use it. If you're a user of AI you'll have doubtless experienced the phenomena of catastrophic forgetting, where the stateless model completely loses the plot. Training is different, it fundamentally changes the matrix weightings of the model itself, permanently altering what it knows. Training is slow, expensive, and one of the reasons why NVIDIA's stock price is so high as it requires a lot of hardware.
Training comes in two flavors:
1. Pre-training This is where foundation models like ChatGPT, Claude, and Gemini are born. The goal is to give the model a broad, general understanding of language and facts. Trillions of data points scraped from the public internet are fed into a massive neural network, whose only job is to learn to predict the next word in a sequence. The result is a Base Model, a repository of generalized knowledge that can form coherent sentences but has no specific purpose or personality.
2. Supervised Fine-Tuning (SFT) The goal here isn't to make a base model smarter; it's to make it useful by aligning it with a specific task or persona. Using a small, high-quality dataset we perform a targeted adjustment of the pre-trained weights. We are teaching the model how to behave by showing it explicit training examples.
The initial plan was to be brutally cheap, using Google's tiny Gemma 2B model which is the smallest I could find on Google Clouds Vertex AI. However, Gemma 2B came with a significant string attached: on Vertex AI, it requires full fine-tuning. This means retraining all two billion of its parameters, a slow, computationally expensive process that creates an entirely new, model artifact for every training run. There was no option for more efficient methods like LoRA (Low-Rank Adaptation), which would just train a small, lightweight "adapter" on top of the base model. I discovered a better option on the platform: Llama 3.2 8B Instruct. It's the perfect sweet spot: far more capable than Gemma 2B, but still small enough to keep the tuning and running costs low.
Instruction Tuning
Fine-tuning an ML model isn't magic, it's pattern matching. If you want a model to "speak Nico," you have to show it as many examples of what I want it to do, in my case examples of Nico speaking. My first attempts were exactly this, feeding the model with my LinkedIn posts formatted as simple text strings:
{"text": "Latest News. Microsoft continues to push CoPilot at unwilling users in more profoundly inane ways."}
Given that I only had 334 training data points in my set, the results were spotty at best. The model's base "helpful assistant" persona was still dominant. Sure, I could force the style with a very specific system prompt, but that's no different from using ChatGPT. The goal is to make the model become the persona. With such little data, the only way forward was to get more specific.
The solution is a more targeted technique called Instruction Tuning. Instead of just showing the model a bucket of text and hoping it gets the vibe, you provide explicit input and output pairs:
{
"input": "Some kind of prompt or question.",
"output": "The desired response in my LinkedIn voice."
}
Looking at my 10 years of posts, I had hundreds of outputs. I had zero inputs, and zero interest in writing hundreds of fake questions for hundreds of real posts.
Synthetic Data Generation: The "Depolisher"
Writing 334 inputs to match my outputs isn't the most exhilarating way to spend an afternoon. Clearly a job for an AI. This approach is called Synthetic Data Generation, and larger more operationalized versions of this are rapidly becoming the standard for training smaller, specialized models. The technique, often called "self-instruct" or "distillation," uses a large, powerful "teacher" model to generate high-quality training data for a smaller "student" model. Research in the field has shown that "Self-Instruct outperforms using existing public instruction datasets by a large margin" and this will doubtless see some commercial application from the likes of Google soon.
Based on this principle I built a small Python script I call The Depolisher. It takes my high-quality, polished LinkedIn posts and feeds them, one by one, to Google's Gemini 2.5 Flash. Gemini is smart, context-aware, and cheap and fast enough to process my entire history in five minutes.
The script runs in two modes, each generating a different flavor of synthetic data to solve the "missing input" problem.
Mode 1: Reverse-Engineering the Prompt (instruct)
The first, most obvious approach is for a Q&A bot. I have the answers, so I asked Gemini to create the questions as if it was a contestant on Jeopardy!.
The Strategy:
"Read this text. Pretend it is the answer to a question. Write the question that would have plausibly resulted in this answer."
The Result:
{
"input_text": "Can you explain Test Driven Development?",
"output_text": "Test Driven Development. Push the code to production, test it, and that drives the development!"
}
A perfect instruction pair, I tried it and again it was hard to tell if this was actually working as I could still see the base persona of the model training through. Perhaps I didn't have the training parameters set high enough, but I tried again, only this time got really really specific:
Mode 2: Style Transfer via "Depolishing" (rewrite)
I wanted a tool that could take a rough draft and rewrite it in my voice. A "Nico-ifier." This is also a perfect task for a small model, essentially turning it into a translator, which is a very specific task I could train it to do.
To train the model I needed pairs where the Input was a bland, boring corporate draft, and the Output was my spicier final version. I needed to teach the model the delta between "Generic Corporate Drone" and "Me."
So, I asked Gemini to surgically remove my soul.
The "Depolisher" Prompt:
system_prompt = (
"You are an expert editing assistant.\n"
"Your job is to take highly polished, opinionated LinkedIn-style writing and rewrite it into a\n"
"bland, neutral, professional draft that preserves ALL of the original information.\n"
"Rules:\n"
"- Preserve every concrete fact, claim, and example.\n"
"- Keep the structure and length roughly the same (no summarizing or expanding).\n"
"- Remove personal voice, jokes, sarcasm, rhetorical questions, and strong opinions.\n"
"- Use straightforward business/professional language.\n"
"- Do NOT mention AI, models, prompts, or that you are rewriting anything.\n"
"- Output ONLY the rewritten text, with no explanations."
)
The Result:
{
"input_text": "The direct displacement of jobs by AI may not be the primary outcome; instead, a different set of operational challenges has materialized.",
"output_text": "Turns out AI isn't coming for our jobs, we are just in a different dystopian reality."
}
Perfect.
It turns out that generating "bland, neutral, professional" text is the default factory setting for most LLMs. By forcing a powerful model to generate the "before" state from my "after" state, I created a perfect dataset to train my model to do the exact opposite.
The Fine-Tuning Process
My initial plan was to be brutally cheap, using Google's tiny Gemma 2B model on the Vertex AI platform. However, Gemma 2B came with a significant string attached: it required full fine-tuning. This means retraining all two billion of its parameters, a slow, computationally expensive process that creates an entirely new, monolithic model artifact for every training run. To make matters worse this full fine tuning requires orders of magnitude more data than I had available. There was no option for more efficient methods like LoRA (Low-Rank Adaptation), which would just train a small, lightweight "adapter" on top of the base model. A full fine tune works best with tens of thousands of training instructions, I only had a few hundred, which is perfect for LoRA.
While setting up this job, I discovered a better option on the platform: Llama 3.2 8B Instruct from Meta. Thanks Zuck. It's the perfect sweet spot: modern, far more capable at four times the size of Gemma 2B, but still small enough to keep the one-time tuning cost at less than $1.
The process was straightforward:
- Upload
training_data_rewrite_v1.jsonlto a Google Cloud Storage bucket. - In Vertex AI, create a new supervised fine-tuning job.
- Point the job at the data file and select the Llama 3.2 8B model.
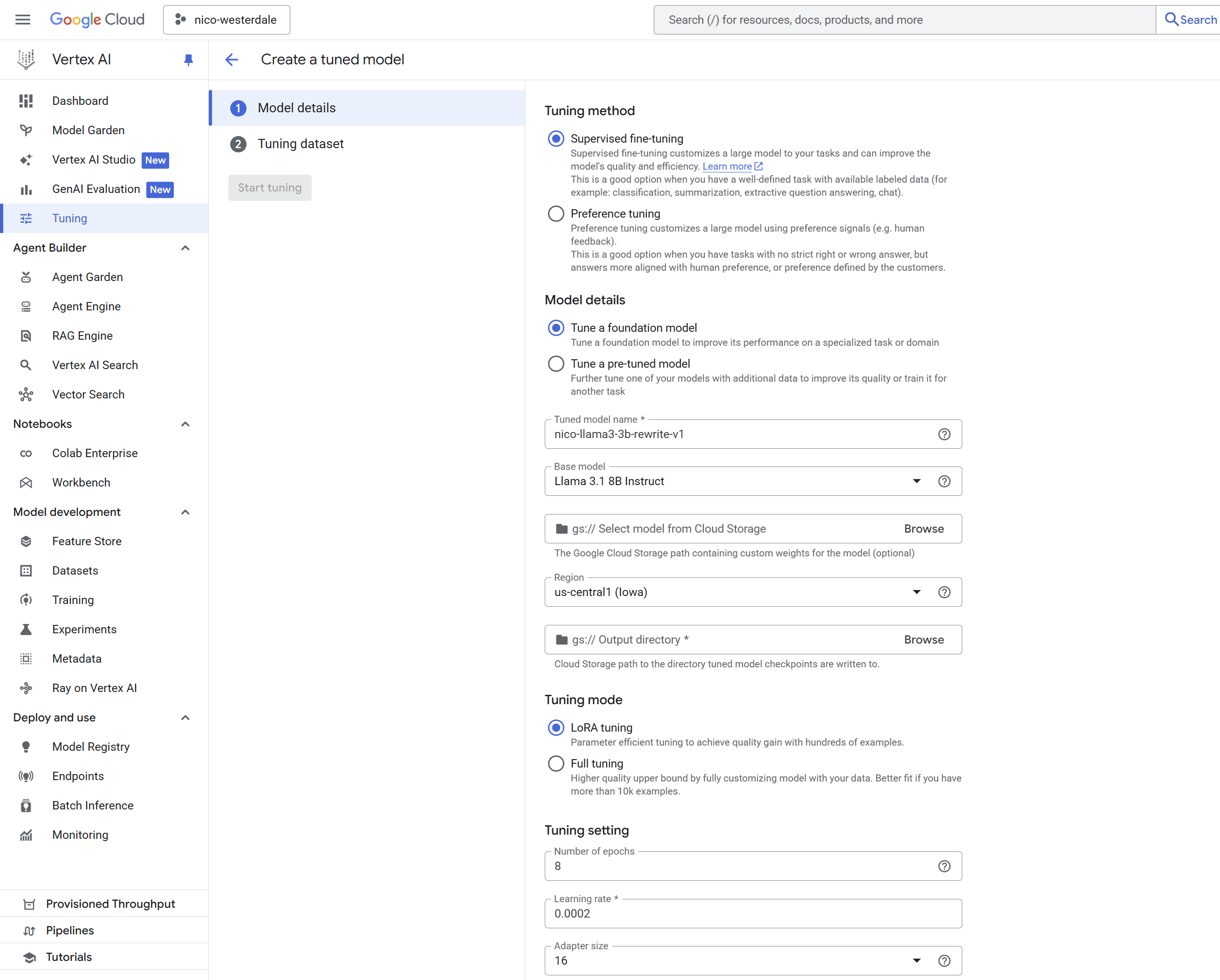
The most critical parameter here is the number of training steps. With a tiny, high-quality dataset, the biggest risk is overtraining. If you train for too long, the model doesn't just learn your style; it memorizes your posts. It becomes a brittle parrot, incapable of generalizing to new text. Train for too few steps, and the model's original "helpful assistant" persona will still bleed through, which is what I was seeing with the smaller Gemma model.
You have to find the sweet spot where you've aggressively overwritten the model's personality without catastrophically "boiling its brain" and making it forget how to form coherent sentences. After a bit of experimentation, the magic number seemed to be 8 epochs a learning rate of 0.0002. It was just enough to force the stylistic change without collapsing the model into a gibbering wreck.
Half an hour later, the job was done. I had a new model artifact in a storage bucket ready for deployment.
The Pipeline
I wrapped all this logic into a small Python project, the linkedin-ai-persona-data-converter
- Ingest: Read the data sludge from
Shares.csv. - Filter: Heuristically discard reposts, comments, and low-effort posts (< 50 characters).
- Transform: Hit the Gemini 2.5 Flash API with the "Depolisher" prompt to generate the synthetic
inputfor eachoutput. - Format: Dump the pristine pairs into
.jsonlfiles.
This is available on my github, should you be interested.
What's Next?
So now I have a model trained on 334 perfect examples that map "Bland Corporate Speak" to "Nico's Voice."
In Part 2, we'll move from data theory to using the model: Docker incantations, running this locally, and skirting some expensive traps to get this running for pennies on a Cloud Run instance.
Stay tuned. Oh and if you have thoughts about this please let me know by commenting on my LinkedIn post about this. I will definitely be using all the comments to train my ML models.