Cursor released version 2.0 yesterday, and I'll admit: the deep UX integration has made it my go to tool over Claude Code. There are genuinely nice things in this release. The multi agent Bot Battle faceoffs let you have different agents running simultaneously to compare approaches. It's clever stuff. The worktree integration means agents won't clash when you have different agents running different tasks, something that I've long been wanting. These are thoughtful features that show Cursor understands the practical realities of what software engineers want out of using AI coding assistants. Cursor was already my daily driver, and the 2.0 drop just made things better.
However, Cursor's UX is moving toward a "Trust me Bro" approach, and it's just not there yet.
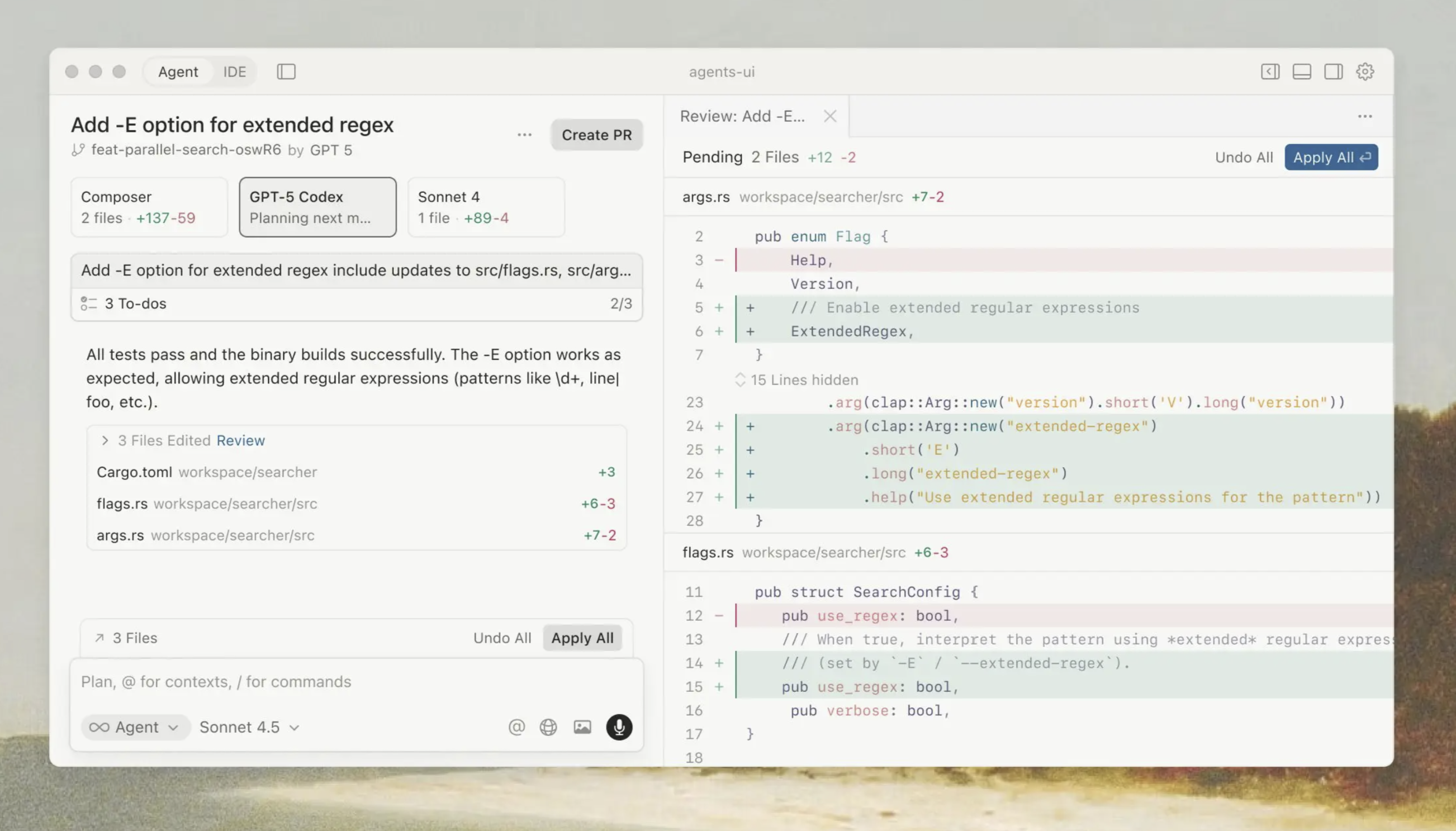
Even with the hot new Composer model trained on reinforcement learning, I'm still reviewing every piece of code the agent generates. The new "Agent" mode is more opaque than it used to be, it tries to decouple the user from the file system, putting your agent front and center. The agent makes changes, shows you what it did, but the reasoning process is less transparent, yes you can drive into every code change and review it, but the clear intention is so surface level review changes and just trust that there's not a giant disaster being made underneath.
The UX pushes you toward a frictionless workflow: "Review" and "Create PR" are right there, ready to go. The interface highlights some of the code changes, but it's really easy to slip into vibe check mode and not perform the due diligence that complex codebases need. Look, it's very cool, don't get me wrong, and Cursor has been and will remain my daily driver. The idea of an agent that can autonomously complete tasks and you just review and merge is the future, but for this to work reliably, really understand the patterns and practices of a complex codebase, the data flows, workflows and patterns within: the Agent has to be right. It's just not.
I find myself immediately falling back to "Editor" mode, where I can pair program with the AI, see suggestions in real time, and maintain control over the process. That's what I have been doing, and like most programmers I've found it a game changer. I spend the last 6 months building a Python project, a language that I've not worked deeply with. Being able to not worry too much about a syntax that I don't know by heart has been revolutionary; it's what AI is excellent at. But while I'm willing to give up control of the syntax of big swaths of lines of code to the agent, I'm absolutely not giving up control of the patterns of my codebase to a clueless fumbling bot that despite workflow files, detailed readme file and very careful question and response prompting just fails repeatedly to "get it".
Maybe I'm too Gen-X. Maybe I need to just spend more time with Agent mode. I can see where it shines: agents running autonomously to write documentation, fix failing tests, or handle routine refactoring tasks, let's have at it. But for my main workflow, building features, debugging complex issues, making architectural decisions, I'm still pair programming with the AI. It's just not good enough to let rip the way the Cursor UX clearly wants me to, and I think the reason is the reinforcement learning.
Cursor fails for me at the first hurdle by halluncinating a typo that isn't there. Hardly confidence inspiring:

Here's what I'll give Cursor credit for: the new Composer model is really fast. Shockingly so in some cases. It seems almost as accurate as Claude and Gemini in thinking mode. I say that because I find I need to refine my prompts a little more, but as it's not sitting there thinking for 20 seconds or more, it's actually often better, and I put that down to the RL training of the model specifically on software engineering use cases.
Composer is a mixture of experts model trained with RL on real world software engineering challenges, completing complex tasks in under 30 seconds, it touts four times faster than comparable models and after a full 24 hours of me using it I can see it. The RL training optimized it for navigating codebases, making edits, and completing tasks within the Cursor environment. This is genuinely impressive engineering, and the speed to accuracy trade off is a huge win. Composer learns from aggregate coding patterns across all training data. It doesn't learn from your codebase, your style, or your preferences. It's a one size fits all model, just optimized for the general case of code editing.
When I review the agent's output and find it's using patterns that don't match my codebase's conventions, that's the model making "generally good" choices rather than "specifically right for my project" choices. When the agent mode feels opaque and I fall back to Editor mode, that's because I can't trust that the agent understands my codebase well enough to operate autonomously.
The "Trust me Bro" UX requires trust. And trust requires the model to understand your specific context. Without personalized RL that learns from your actual codebase and feedback, that trust gap will always exist.
That's what's more interesting than the impressive RL work Cursor did do: what they haven't built is a reinforcement learning feedback mechanism that learns from your actual codebase and gets better over time based on your agentic use patterns. This gap reveals where we are versus where we need to be in personalized code generation.
What Cursor Actually Did with RL

Composer is a mixture of experts model (MoE), trained with reinforcement learning on real world software engineering challenges. The MoE architecture works by routing requests to specific expert pathways based on the task, instead of activating the full model for every request. That reduces overhead and allows the massive speed boost we're seeing. The RL training ensures those routing decisions are optimized for real coding scenarios. What they did to train it, basically, was run tens of thousands of software engineering requests in a harness called "Cursor Bench", scored the outcomes, and then fed those results back using RL to tweak the weights of the transformer matrices.
This is exciting because it's one of the first large scale production LLMs explicitly designed for agentic code editing workflows. Most code generation models are trained on code snippets in isolation. Composer was trained on the actual task of "navigate this codebase, understand context, make changes, verify correctness", the full loop that developers actually use.
It's like giving and F1 car to ten thousand drivers and getting them to do a lap, and tweaking that car each time based on their feedback; it's going to get faster. Cursor also uses RL for the inline "tab" suggestions, and is clearly using real world feedback to continuously continuously tune their models. It's still just one car though, we all have to share.
When you're in Agent mode watching Composer navigate your codebase, it's making decisions based on what works in general, not what works for you. That's why the Bot Battle feature is interesting. It's acknowledging that you might want to try multiple approaches because no single approach fits your specific codebase perfectly. To me that's a workaround, and a good one, but not a solution.
What They Didn't Build: Personalized RL from User Feedback
This is what would actually enable the UX that Cursor is pushing. What Cursor hasn't done, and what would be genuinely transformative, is implement RL that learns from your specific codebase and interactions. Imagine a system that:
- Learns your coding style preferences from your actual edits
- Understands your project's architectural patterns and conventions
- Adapts suggestions based on what you've accepted, rejected, or modified
- Gets better at generating code that fits your codebase over time
This would require a feedback loop where:
- The model generates code
- You accept, reject, or modify it
- That feedback is used to update a user-specific reward model
- The model's policy is fine tuned, or the routing changes, based on those rewards
- Future suggestions align better with your preferences
Right now, when I fall back to Editor mode, I'm providing the feedback that could train my system the way I want it. Yes Cursor does use it in aggregate along with everyone else, but it isn't using it to build a corpus of knowledge that's truly integrated into my LLM. I still have to share. Every time I modify a suggestion, reject code that doesn't fit my patterns, or accept code that aligns with my conventions, that's signal that's not being captured to improve the model for my specific use case.
Why This Is Hard: The Research Landscape
The research community has been exploring personalized RL, but the solutions reveal why it's difficult to implement in production. Feedback is expensive, noisy, and sparse. Users don't want to rate every suggestion. Sometimes you accept bad code, sometimes you reject good code. Most suggestions are fine, only outliers generate strong signals.
Then there's the cost problem. Fine tuning language models per user requires massive GPU resources, storage for user-specific adapter weights, and infrastructure to serve millions of personalized models. Even efficient approaches like LoRA (Low-Rank Adaptation) still need significant compute. In context personalization means larger context windows and higher token costs. Neither scales well.
But here's the thing: in Editor mode, I'm already providing implicit feedback. Every edit I make, every suggestion I accept or modify, every pattern I establish. The challenge isn't collecting it. It's using it effectively to personalize the model without destroying the UX or breaking the bank.
The research shows several approaches, but each reveals why this is hard in production:
- PEBBLE: Uses off-policy RL (SAC-based) with preference-based reward learning, actively querying human preferences and relabeling past experiences for sample efficiency. But it was tested on simple grid worlds and robot control, not the complexity of code generation where feedback is expensive, noisy, and sparse.
- CANDERE-COACH: Employs Q-learning with noise-filtering mechanisms for human feedback. Addresses the critical problem that users make mistakes, accepting code with subtle bugs or rejecting correct but unfamiliar code. Still, this doesn't solve the fundamental sparsity problem for individual codebases.
- DQN-TAMER: Combines Deep Q-Networks (value-based Q-learning) with TAMER's human feedback framework, showing agents can outperform when given both human feedback and distant rewards. But it assumes real time feedback availability, which is problematic for code generation where good review requires context and time.
- Crowd-PrefRL: Uses preference-based RL to learn reward functions from aggregated human preferences, optimizing policies to align with collective feedback. This solves data sparsity by pooling feedback, but it's the opposite of personalization: it optimizes for the average user, not individual preferences, which is probably closer to what Cursor is doing with Composer.
- ACE-RLHF: Applies RLHF (typically PPO or similar policy gradient methods) to fine tune LLMs for automated code evaluation and feedback generation. It generates Socratic feedback to improve code repairs, which is interesting but addresses a different problem: helping models evaluate their own code, not learning user preferences.
Memory as a Pragmatic Patch
Full personalized RL from user feedback using these Q-Learning like systems is expensive and complex, but what if you could approximate it? That's where memory systems come in.
Instead of fine tuning a model per user, you store user-specific knowledge in a separate memory system. The model queries this memory during inference, pulling in context about your codebase patterns, your preferences, your architectural decisions. It's like giving the model a cheat sheet it can reference, but the cheat sheet is built from your actual interactions.
Cursor already has a Memory feature that uses a sidecar-based design. It automatically creates memories from conversations, allows manual memory management through Rules, and maintains Memory Banks for project-specific information. But it's focused on maintaining context within sessions, not learning from feedback patterns. It's pure retrieval (RAG), not RL-based. When I modify a suggestion or reject code, that's implicit feedback that could be stored in memory and referenced later. Right now, Cursor's Memory captures what you explicitly tell it to remember, but it doesn't learn from your acceptance patterns, your edits, or your rejections. It's memory without learning.
Google's Agent Builder Memory Bank does exactly this for its Vertex models. It maintains persistent memory for agents, storing user preferences, code patterns, and context that gets retrieved during each interaction. The agent doesn't need to be retrained, but it can access personalized knowledge. It's essentially RAG applied to user preferences instead of documentation. Like Cursor's Memory, it's retrieval-based, not RL-based.
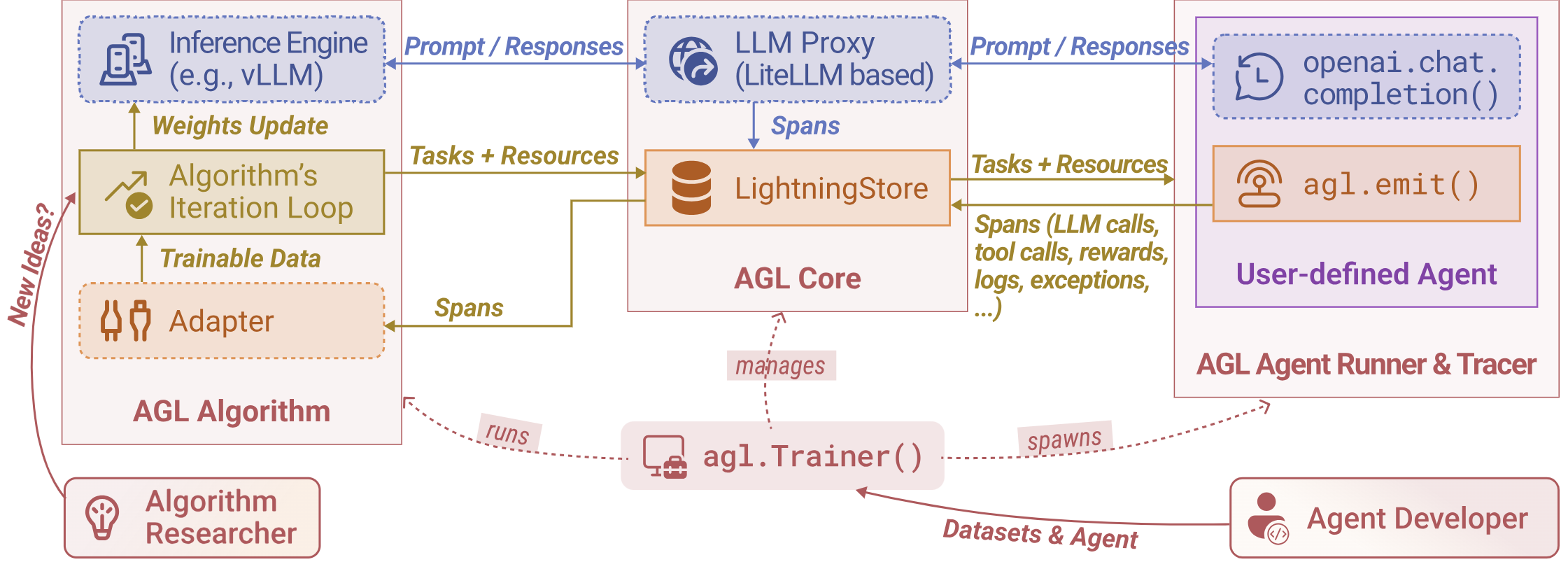
Then there's Microsoft's Agent Lightning, which is more interesting because it's specifically about training agents with RL in a framework-agnostic way. It acts as an intermediate layer between agent frameworks and the LLM, exposing an OpenAI-compatible API that agents connect to. Behind the scenes, it uses a sidecar-based design to non-intrusively monitor agent executions, collecting execution traces, errors, and reward signals. These traces get converted into transition tuples for RL training via verl (their RL infrastructure), which supports algorithms like GRPO to update the intermediate model layer. The updated intermediate model is used in the next rollout cycle, creating a feedback loop. It supports multiple RL algorithms (GRPO, PPO, and others), all without requiring you to rewrite your agent code. It's still aggregate learning in many ways, but the infrastructure is there for per user personalization through actual model training, not just retrieval.
What makes Agent Lightning potentially more promising than pure memory systems is that it's actually training an intermediate model layer (adapters, prompt optimizations, task-specific components), not just consulting a database. It doesn't fine-tune the base LLM itself, but rather trains intermediate components that adapt the base model's behavior. The infrastructure could support per-user personalization, but currently it's designed for aggregate training across all users. If you wanted true per-user personalization with Agent Lightning, you'd need significant individual usage before the RL training produces meaningful improvements for your specific use case.
Memory systems are a pragmatic middle ground. They give you personalization without per user model training. They're available now, they work with existing models, and they're significantly cheaper than full personalized RL which is computationally prohibitively expensive. However they're still just consulting an external knowledge base or acting as a last-stage filter. The model itself doesn't internalize your patterns. When the memory system retrieves the right context, great. When it doesn't, you're back to the same generalist behavior.
It's a patch, yes. But sometimes patches are what you need until the real solution arrives.
What about Self-Hosting
What if you self-hosted your own LLM? Could you use RL to modify it directly? Yes, you absolutely can. Tools like TRL (Transformers Reinforcement Learning) and LLaMA-Factory support RLHF training on self-hosted models, letting you fine-tune open-source models like LLaMA, Mistral, or GPT-J using PPO or other RL algorithms. You'd collect feedback from your actual usage, train reward models, and optimize the model weights directly.
Enterprises are doing exactly this. Companies in regulated industries (healthcare, finance, legal) self-host LLMs for data privacy and compliance, then use RLHF to customize them for their specific needs. But it's expensive. Training a 7B parameter model with RLHF typically requires multiple A100 GPUs, and larger models need even more. You're talking about significant compute infrastructure, specialized ML expertise, and ongoing maintenance.
Is there a turn-key cloud RLHF service? Not really. AWS, Azure, and Google Cloud offer supervised fine-tuning services, but not RLHF as a managed offering. You can run RLHF training in the cloud using their GPU infrastructure (Azure ML, AWS SageMaker, Google Vertex AI), but you're still bringing your own tools like TRL or LLaMA-Factory and managing the training pipeline yourself. It's cloud-hosted, not cloud-managed. Someone needs to build the managed service layer.
For personal use? Unless you have a datacenter, it's not feasible. But for enterprises that already have GPU infrastructure and need true per-organization personalization, self-hosted RLHF training is a real option. It's the most direct path to a model that actually learns your patterns, not just retrieves them.
So where are we?
Cursor 2.0's Composer is genuinely impressive. Using RL to optimize for real world code editing workflows is the right direction, and the MoE architecture is a smart engineering choice for speed. But the absence of personalized RL from user feedback is why I'm still in Editor mode most of the time.
We're in the era of one size fits all code generation. The next era, where tools learn your codebase, your style, and your preferences from your actual usage, is what would actually enable the "Trust me Bro" UX that Agent mode is aiming for. Memory systems offer a pragmatic patch in the meantime, but true personalization requires solving the cost, feedback, and continuous learning problems at scale.
That's the challenge Cursor, and everyone else, needs to solve. The research exists. The hard part? Making it work in production, at scale, without breaking the bank or destroying the UX.
Until then, I'll keep using Editor mode for my main workflow, pair programming with the AI, providing all that implicit feedback that could, but doesn't yet, make the model understand my codebase instead of just codebases in general.