My son and I have been watching Gotham Chess' hilarious YouTube series on LLMs failing to play chess. ChatGPT versus Google's AI, ChatGPT versus Grok, the whole parade of language models squaring off on the chessboard. It's become a bit of a ritual for us. Not because the chess is good, but because LLMs are gloriously, predictably, terrible at playing the game.
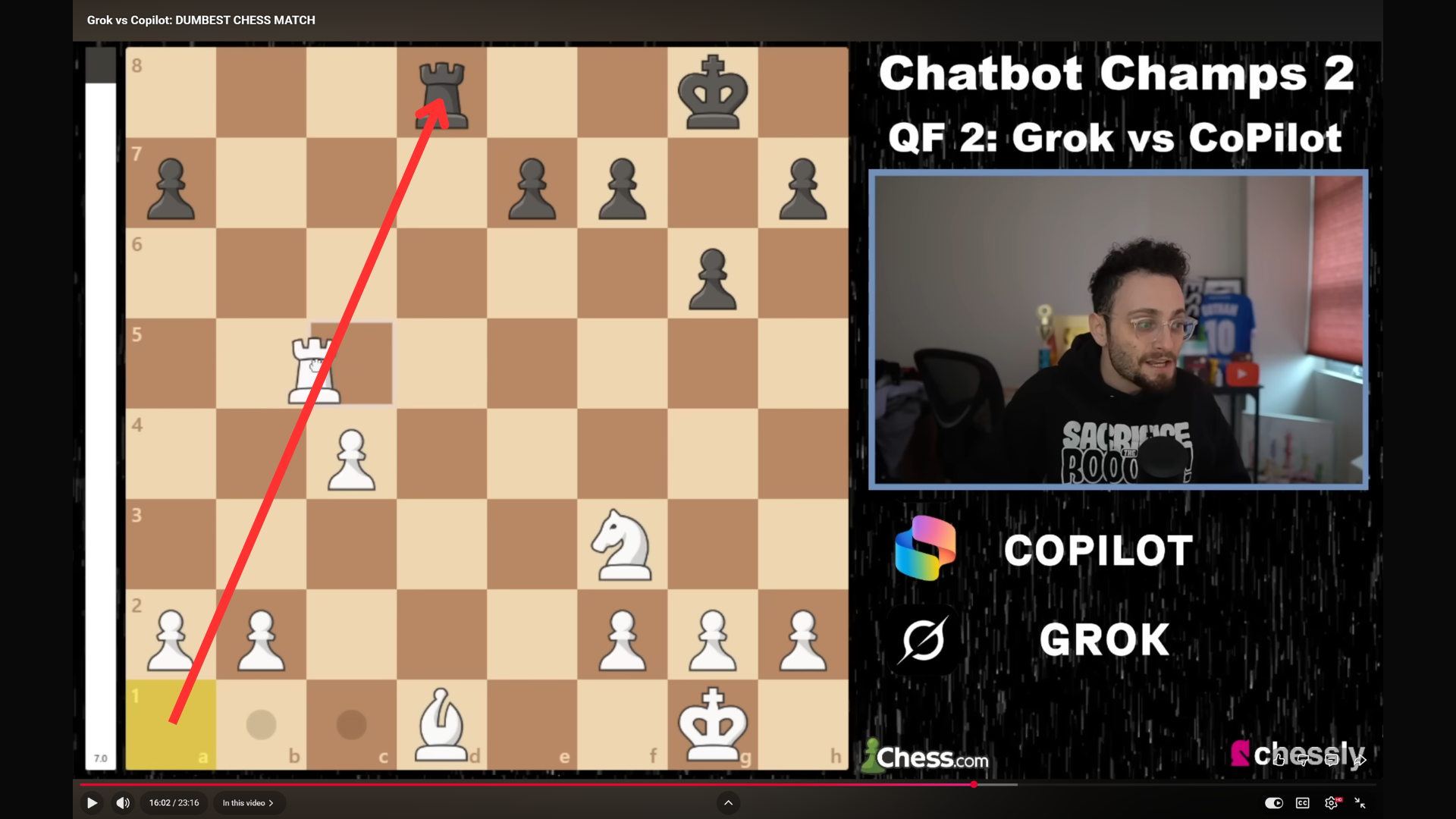
Gotham Chess: Grok vs Copilot. Disaster ensues when Grok summons in a Rock. Copilot initially complains about the illegal move, but decides to let Grok make it anyway to exploit an attack by it's Queen, neglecting to realize that Grok's Bishop is somehow allowed to move sideways, setting up a flying attack from The Rook!
The LLMs trade off pieces like they're clearing out a garage sale. Rooks left hanging, knights blundered for nothing, queens handed over with a shrug. Then there are the illegal moves: castling when the king has already moved, sliding bishops through pawns, moving pieces that aren't even there. At some point you stop being surprised and start wondering what's actually going on inside those billions of vector parameters. The answer, it turns out, is not much. There's no real idea, no coherent picture of the board, no sense that the model understands it's playing a game with rules.
Despite how advanced these models are, they can't even consistently follow the rules of the game. The "let's get an LLM to do it" refrain has become a reflexive reaction in startup business leadership and has graced a multitude of pitch decks put in front of would-be investors. Yes, there are times when LLMs are phenomenal at solving problems, but this is by no means true for all classes of problems. There is huge swathes of computer engineering where using an LLM is a gloriously terrible idea, just like using an LLM for playing chess is a gloriously terrible idea, despite Gotham's amusing content. This isn't a matter of scale or training data. It's baked into the fundamental ways that LLMs are built and operate.
Opening Gambit: A Facade of Reasoning
When you start watching LLMs square off in a chess match, things actually go quite well, and most LLMs are competent with the standard openings. This makes sense given that LLMs are trained on a huge swath of data, including millions of standard openings starting with e4 e5, Nf3 Nc6, the Italian, the Sicilian, the Ruy Lopez. These are well trodden paths with games going back centuries.
So what's happening? The model is mapping the current sequence of tokens onto a high dimensional vector space and sampling from the probability distribution that its training data has learned. Or, put simply: it's memorized the openings. If the board position is in the training set repeatedly, as most openings are, the LLM will be able to find it and recognize what other players often do next. When the position is well represented in that training data, the next move is usually the most commonly accepted best line or a reasonable alternative. It's important to realize that the LLM isn't reasoning about the board at all here. It's doing what it does best: pattern matching over a massive training set of data. For the repeating patterns in chess openings it will flawlessly pattern match and suggest the most reasonable move, and even tell you why it's doing it. Neato.
Midgame: Clock is Ticking on Training Data
Once the game moves past standard openings into a midgame, LLMs really struggle, and the dropoff in skill is sharp. There are more possible chess positions than any training set could ever contain, and the vast majority of midgame positions the model encounters are ones it has never seen before. The model is still mapping token sequences onto that high dimensional vector space and sampling from the probability distribution it learned. But now that distribution is sparse. The current position might be close to something in the training set, but it's not the same. Or, put simply: it hasn't memorized this position.
The LLM is guessing from similar looking positions, and the guesses are increasingly ungrounded. The model is still predicting the next token, but it's not maintaining an internal representation of the board. One missed capture, one inference slip, and the model's internal state diverges from reality. It thinks the rook is on a1 when it's actually on a8. That's when you get bishops sliding through pawns. The model isn't seeing blockers. It's sampling from a distribution that's no longer anchored to the actual board. Researchers call this state tracking failure. There's also pointer misbinding: when the model knows it needs to move a rook but grabs the wrong one. Two rooks, same token type, different contexts. The attention mechanism conflates them. The strategic intent of how to play is often correct, the LLM knows midgame theory as it's memorized books on the subject, but execution fails. Add in line of sight hallucinations, where the model slides a piece through another because it doesn't geometrically track blockers. Statistical probability overrides the constraints of the rules of the game. The problem is that pattern matching doesn't work when the pattern isn't there to match from.
Endgame: A Checkmate with Reality
By the endgame, the collapse is total. The model's internal representation has drifted so far from the actual board that illegal moves become routine. Castling when the king has already moved. The LLM moves pieces that aren't there; the hilarious Gotham refrain of summoning in "THE ROOK" to sacrifice itself, yet only to reappear a few moves later. The probability distribution that the model is sampling from is no longer grounded in the training data at all. The position is so far from anything it's seen that the model is making wild guesses full of illegal moves. The vector space mapping returns almost nothing of value as the positions are so novel. The model keeps producing moves because that's what it's trained to do, but there's no coherent connection between those moves and the actual state of the board or even the rules of the game. This is because LLMs cannot apply a complex ruleset to a novel complex situation. They're just not built for it unless they have been heavily trained to pattern match on similar situations. Even then they are not reasoning, they're just checking to see if something has happened before, and mimicking it.
LLMs in Action
Let's see how ChatGPT and Gemini both handle the same position:
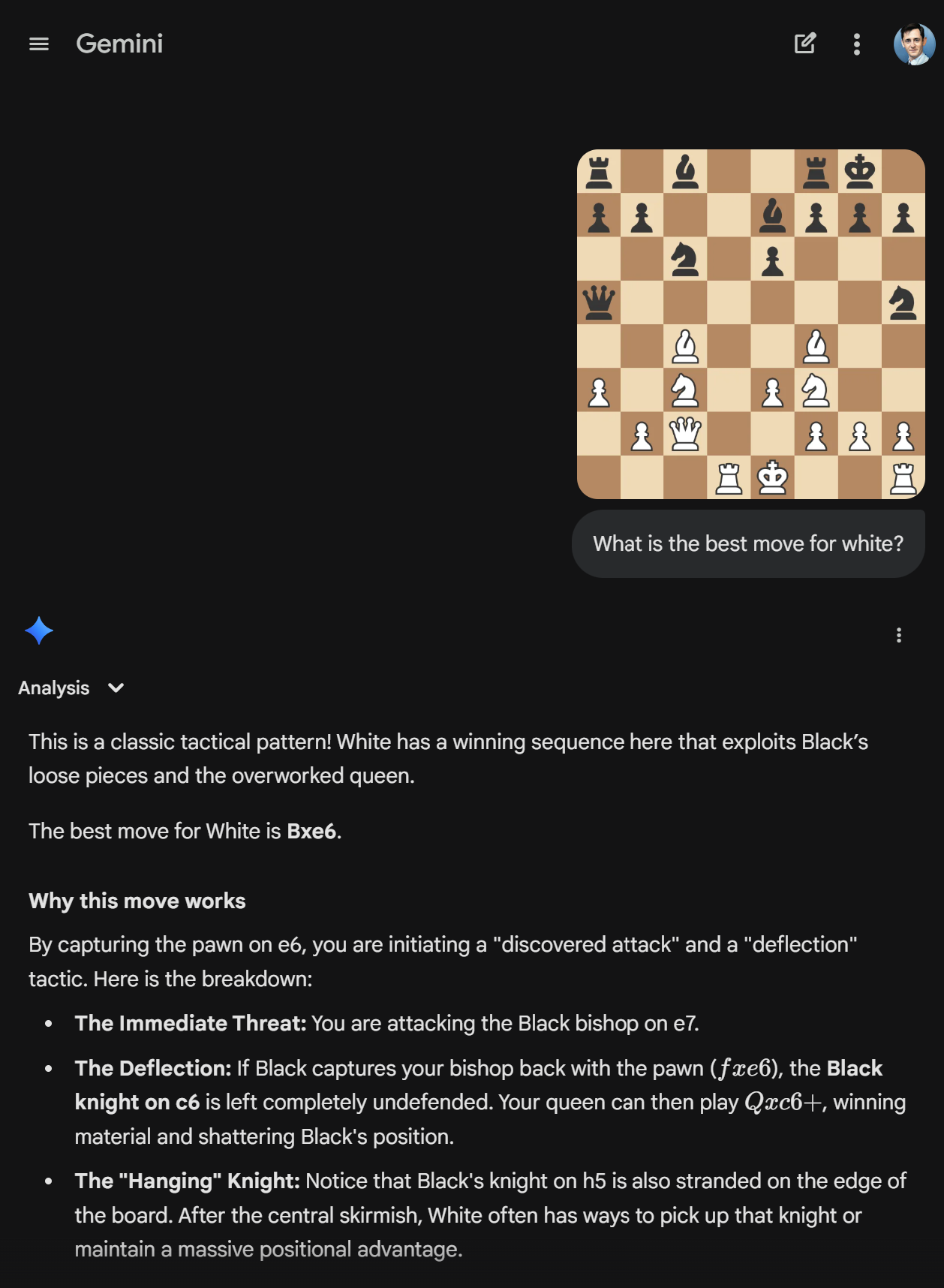
Gemini suggests the white Bishop should take the black Pawn on e6, stating incorrectly that the black Bishop on e7 is being attacked. If white's Bishop is taken by the black Pawn on f7, Gemini suggests that the Queen should teleport over the white Knight to capture the black Knight on c6, stating it's undefended, when it is in fact defended by the Pawn on b7. This suicidal Queen move is also somehow a check to black's well defended King.

ChatGPT makes the same move, and is so confident about sacrificing its white Bishop to check the black King, it marks the move with an exclamation mark, denoting that it's a great move. It neglects to see that it's not actually a check due to the black Pawn on f7, which can promptly take the white Bishop. Its line of thinking then suggests a counterattack to the black Rook taking the sacrificed Bishop by the white Queen teleporting over the white Knight to c4, or the Queen moving to g6, where the black Queen can promptly take it.
Computational Complexity
Let's understand the sheer size of the game of chess. Despite just 64 squares and 32 pieces, the number of possible games is huge. Claude Shannon estimated there are roughly 10^120 possible chess games, that's 1 followed by 120 zeros. For comparison, the observable universe contains about 10^80 atoms, that's significantly smaller. The number of possible chess games is so mindbogglingly massive that it would be impossible to build a computer to store every single game even if we were doing it at the atomic level. So, put simply, we can't "solve" chess. We would never have the computational power to deterministically map every single possible game and position and always determine the best board position. This is why both human and computer players have to do four things:
- Memorize the best thinking for common lines
- Create strategies that work in general and pattern match them to the current board position
- Look ahead to determine which move will put the player in a higher probability of winning
- Guess
As we've seen, LLMs are okay at 1, bad at 2 and just awful at 3 and get worse at 4 the further from the starting position the game progresses.
Stockfish: The Grandmaster's Approach
Stockfish is the world's most advanced computer chess engine ever produced and far outclasses humans and LLMs alike. It does all the things that LLMs cannot. It maintains an explicit representation of the board. Every piece, every square, updated deterministically after every move. The engine has a move generator that produces only legal moves. It applies the rules of chess directly. Castling, en passant, piece movement: all encoded as logic, not approximated from training data.
For look ahead, Stockfish uses minimax search with alpha beta pruning. That is to say it explores a tree of possible moves, evaluates positions at the leaves, and backs the scores up to choose the best line. It can't search the whole tree, nobody can, but it searches millions of positions per second and cuts branches that can't possibly affect the outcome. This prunes the probability tree to more targeted results. The search is the opposite of pattern matching; it's actual computation. The engine also uses opening books for common lines and endgame tablebases for solved positions, but the midgame is pure search and evaluation.
Modern Stockfish adds in a small neural network for position evaluation. The key difference from an LLM: a neural net takes the board state as structured input and outputs a single score. It doesn't generate moves. It evaluates the board and outputs a score indicating whether the position is better or worse for one side. The search algorithm does the reasoning. The network just answers "how good is this position?" The combined approach in how Stockfish is built is the right architecture for the problem of playing chess well.
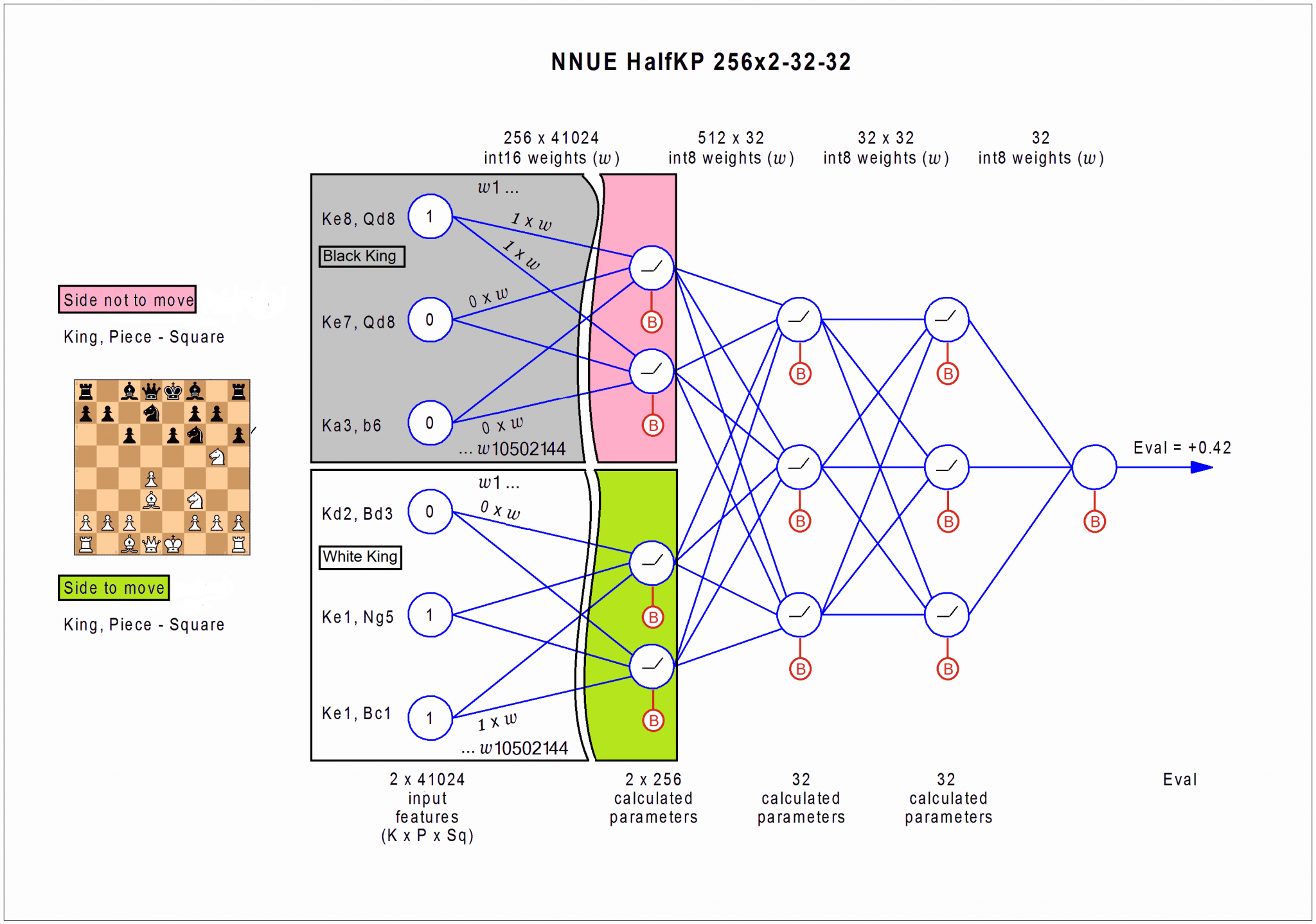
Stockfish's Neural Net layers in action. Image from the Chessprogramming wiki.
Won't LLMs just get better?
Stockfish's Elo (its numeric chess rating) is around 3900. For context, Magnus Carlsen, arguably the world's strongest grandmaster of all time, is ranked around 2880. Chess.com ranks me around 1200 as a somewhat passable intermediate player. LLMs rank anywhere from 500 for standard models like Claude Opus 4.5 to over 1000 or so for the best thinking models like Gemini 3 Pro and GPT-5.1. However, even the highly ranked models routinely produce illegal moves.
The thinking models do better because they get a "thinking budget." Instead of outputting the move immediately, they generate hundreds or thousands of tokens of internal reasoning first. They can write out the board state, list candidate moves, check for legality, and correct themselves before committing. It's verification through extended chain of thought. They catch their own mistakes in the scratch pad before the final answer. That's why legality rates jump from abysmal to 99% or higher with thinking models. But here's the ceiling: they're still not searching. Stockfish explores millions of positions per second, evaluates each one, and backs scores up a tree. The LLM is just pattern matching to a training set with more room to try and verify, poorly. The architecture doesn't change. No minimax. No alpha beta pruning. No explicit move generator that guarantees legality. The transformer is still predicting the next token based on a training set. It's doing a better job of checking its work, literally by throwing expensive compute at the problem, but it's not doing the work that Stockfish does. More compute, bigger models, longer thinking budgets will squeeze out incremental gains. They won't ever close the gap to 3900 Elo. The gap is architectural, not scalar.
Are There Hybrid Chess Models?
Yes. The research points toward combining LLMs with the right tools rather than hoping the LLM will become the right tool. DeepMind's 2024 work on "Mastering Board Games by External and Internal Planning with Language Models" shows two approaches. In external search, the LLM guides Monte Carlo Tree Search rollouts and evaluations. In internal search, the model generates an in context linearized tree of potential futures before choosing a move. Both rely on pretraining the model on chess domain knowledge, which minimizes hallucinations and improves state prediction. The result: Grandmaster level performance, with a search budget per move comparable to human grandmasters. The LLM isn't doing the search alone. It's guiding it, or approximating it in context. The search does the heavy lifting.
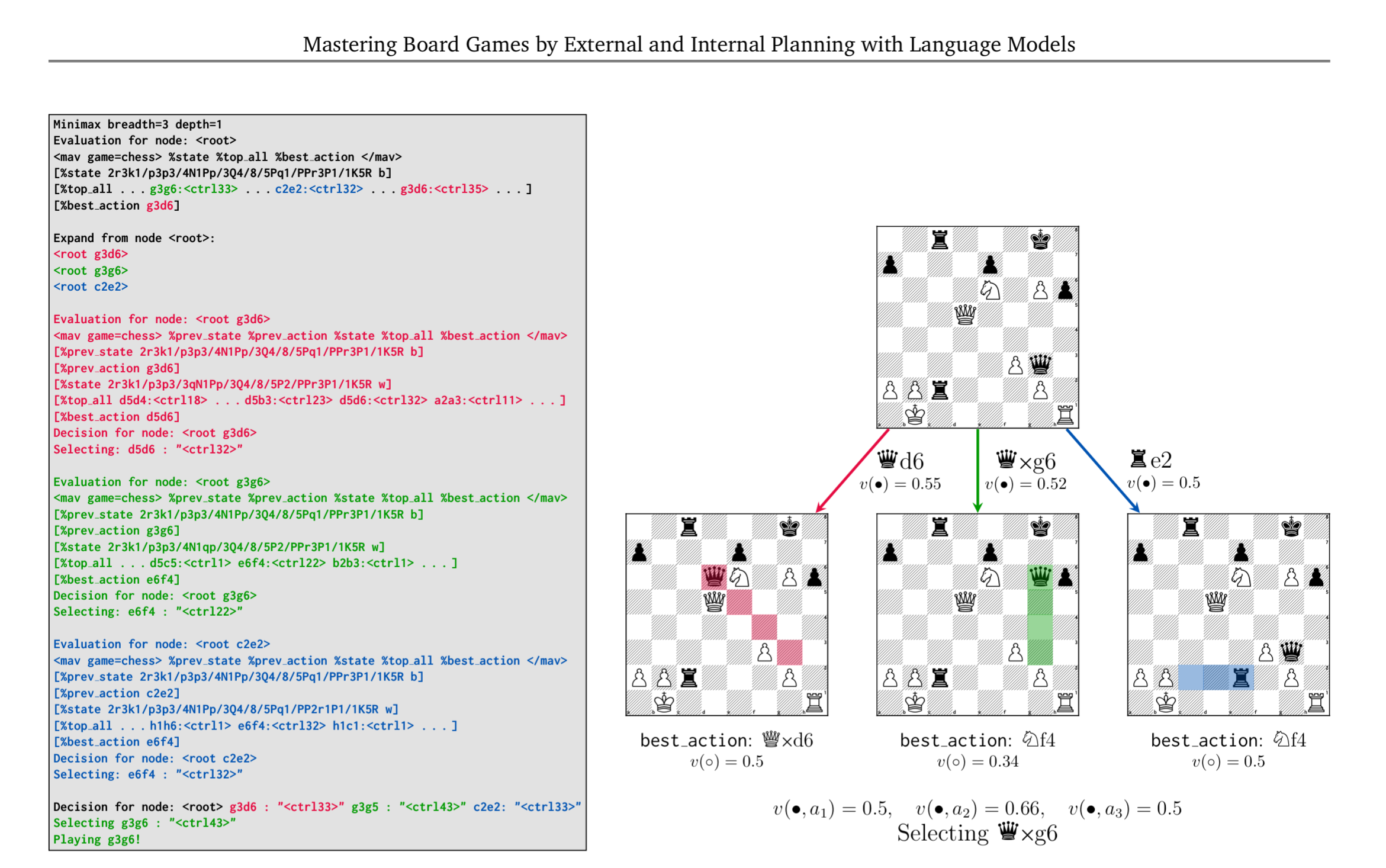
External search in action from Google DeepMind, evaluating board positions.
The LLM CHESS benchmark (December 2025) evaluates over 50 models on win rates, move legality, and hallucinated actions. Top reasoning models are now tested against engines like Komodo Dragon for Elo anchoring, since they've saturated random opponent evaluations. The public leaderboard tracks which models can actually finish a game without illegal moves. The takeaway: hybrids work when you add the missing architecture. LLM for language and high level strategy, engine or search for legality and tree exploration. You're not fixing the transformer. You're wiring it to the right tool.
Beyond the Board: The Same Gambit
The same pattern is being generalized beyond chess. Language Agent Tree Search (LATS), from ICML 2024, uses Monte Carlo Tree Search with LLMs for reasoning, acting, and planning across programming, web navigation, and question answering. The LLM proposes actions; the environment (test results, simulators) provides feedback; the search explores which trajectories succeed. 92.7% pass@1 on HumanEval, 75.9 on WebShop. External verification is the key. Research on plan verification for LLM agents shows that external verification significantly outperforms self critique: "significant performance gains with sound external verification" versus "significant performance collapse with self-critique." The LLM plans. Something else verifies. Agentic frameworks like AgentFlow and OctoTools use separate planner, executor, and verifier modules.
Anthropic's much lauded work on Claude planning and subagents fits the same mold. Anthropic's multi-agent research system uses an orchestrator worker pattern: a lead agent plans and delegates to specialized subagents (Explore, Plan, general purpose) that run in parallel with their own context windows and tools. The Plan subagent researches the codebase before the main agent presents a plan. The Explore subagent does read-only discovery. Each subagent is a separate capacity. The lead agent doesn't do everything. It decomposes, delegates, and synthesizes. Their internal evals show 90% better performance than a single agent on complex research tasks. The architecture: one agent plans, many agents execute with specialized roles and tools. Same lesson. When the problem exceeds what a single context can hold, or when different steps need different capabilities, wire the LLM to the right structure. Subagents, external search, verification modules. The chess lesson applies: when the problem has strict constraints or exceeds single-agent capacity, wire the LLM to tools and structures that can verify or execute.
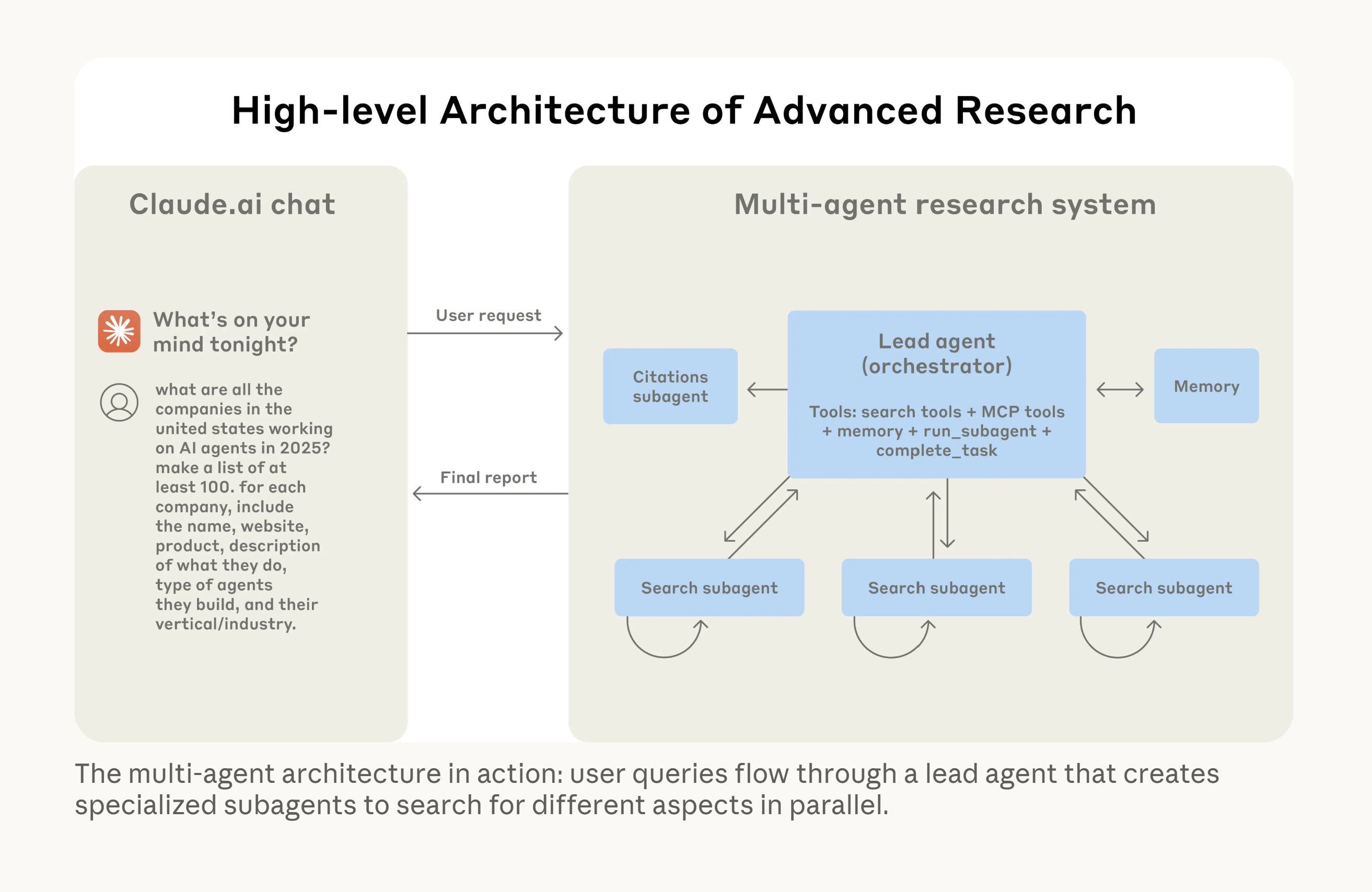
Don't Blunder Your Software Project
Chess is a pure diagnostic. It exposes a class of problems where LLMs fail not because they're undertrained, but because the task fundamentally doesn't fit the architecture of where LLMs excel. Stateful, rule-bound, sequential reasoning with strict constraints. Sound familiar? That describes a lot of what we build. Configuration validation. Workflow engines. Financial calculations. Anything where the rules are absolute and one wrong step invalidates the whole chain. The size of the problem matters too; at big data scale, LLMs flounder. Adding in an orchestration layer doesn't fix it. Subagents, lead agents, delegation: they help when the problem is about capacity or parallelization, when a complex problem can be chunked into small unconnected tasks. They don't help when the core task is state tracking and rule application. The LLM is still the wrong architecture at the center. Adding more LLMs around it doesn't change that.
The knee-jerk "let's just use an LLM" refrain makes sense for plenty of tasks. Natural language to SQL, summarization, code completion, translation, drafting emails, document Q&A, brainstorming, first drafts, refactoring suggestions, test generation, documentation, chat interfaces, content moderation triage, the list goes on! These are problems where statistical approximation works. A slightly wrong suggestion is still incredibly useful if we are unbound by a tight ruleset. By comparison a slightly wrong chess move is illegal. A slightly wrong financial calculation is fraud. The problem class matters. When the output has to be exact, when the rules are rigid, when the state has to be tracked precisely across many steps, an LLM might be the wrong tool. Not because it's dumb. Because it's built for something else entirely.
I use LLMs every day. They're extraordinary for the right problems. But watching Gotham Chess tear into ChatGPT's queen blunders with my son, I'm reminded that "AI" isn't one thing. It's a collection of tools, each with strengths and limits. Knowing when to reach for an LLM and when to reach for a rules engine, or a state machine, or an actual chess engine, is the skill. Gotham's content comes from the mismatch between expectation and reality of some of mankind's most advanced technology failing so spectacularly. The engineering lesson is to avoid creating that mismatch in prod.
Update: Orchestration and Fine-Tuning
Following a robust discussion about this article on Reddit (50k+ views and counting), two technical counter-points stood out.
1. Orchestration vs. Computation: "Stockfish as a Skill"
A common suggestion is that we can simply "fix" LLM chess by using the Model Context Protocol (MCP) to give the model access to Stockfish as a tool. While this results in Stockfish level play, it confirms the architectural argument: the LLM isn't calculating chess; it is a high-level orchestrator.
In this setup, the LLM excels at Intent Recognition (understanding the user wants to play a move) and Tool Use (calling the engine), but it has completely offloaded the State Tracking and Logic to a symbolic system. It’s an example of why we should wire LLMs to specialized architectures rather than trying to force a Transformer to be a calculator.
2. The Uncanny Valley of Fine-Tuning
It is possible to tune LLMs via supervised learning and get strong results far better than the off-the-shel LLMs. As Redditor Individual_Prior_446 notes, models trained on millions of games from the Lichess Elite Database encode board-relevant patterns in their weights. Google DeepMind's ChessBench paper pushes this further: a 270M parameter transformer trained on 15 billion Stockfish-annotated action-values achieves 2895 Lichess blitz Elo against humans, that's grandmaster level, with no explicit search at test time. That's an astounding result. But here's the catch: it still requires Stockfish. The model is a student of Stockfish, not a replacement. Stockfish 16 sits at roughly 3800 Elo; the researchers' primary finding is that "our largest model achieves good performance, it does not fully close the gap to Stockfish 16, and it is unclear whether further scaling would close this gap or whether other innovations are needed."
Smaller specialized models tell the same story. Chess-Llama (23M parameters, ~1400 Elo) only generates legal moves 99.1% of the time. Karvonen's Chess-GPT research shows a linear probe can reconstruct a functional board state from internal activations with 99% accuracy, but reconstructability is not the same as existence. The probe shows that we can decode board-like structure; it does not prove the model "has" a board. There is no Board object, no piece array, no explicit state. Karvonen's model still fails on edge cases like pinned pieces, with an illegal move rate of 0.2% to 0.4%. Humans don't store chessboards as object-oriented Board() models either, and some of us are really good at chess, but these models reside in an "Uncanny Valley" of logic where the gaps matter’s.
The ChessBench paper surfaces the architectural limits directly. It does not prove the model "has" a board, or "sees" the board, in any meaningful sense. There is no Board object, no piece array, no explicit state as one might have a "Board()" object in object-oriented code. Just weights and transient activation vectors. The model doesn't maintain a world model; it has distributed patterns that happen to correlate with one when we project our interpretation onto them. Now humans don't store chessboards in our brains as object-oriented Board() models either, and some of us are really good at chess.
The ChessBench paper surfaces the architectural limits directly, with some facsinating results. The model uses FEN (board state only), not full game history, so it cannot detect threefold repetition; the authors note it "cannot plan ahead to minimize the risk of being forced into threefold repetition." Against bots, Elo drops by roughly 600 points compared to humans (2299 vs. 2895), in part because bots don't resign in lost positions and the model sometimes fails to convert overwhelming wins, paradoxically settling for draws when multiple moves map to the same value bin. A state-based predictor without search cannot guarantee it will commit to a single winning line. Supervised learning can approximate Stockfish, but it still needs Stockfish to create the training data; another 1000 points of ELo is a huge gap to cross.
I'd argue these models still reside in an "Uncanny Valley" of logic. Despite its specialized training, these models approach playing, representing and moving pieces in chess vastly differently from how Stockfish, a neural net based search algorithm would.
Emergent vs. Symbolic Models
This highlights the fundamental difference between an Emergent World Model (probabilistic) and a Symbolic World Model (rule-bound, deterministic). My motivation for writing this article was to highlight that probabilistic LLMs are often not the most appropriate tool for the problem at hand. Yes, training can help, sometimes dramatically, but training requires access to large datasets to train from, and for some problems those may not be available; we may not know what "good" looks like in order to approximate it with supervised learning, and training is often difficult and expensive. There are also many times in software engineering when having a 100% accurate state based system is simply the best tool for the job. Could a future LLM trained on Stockfish data eclipse the 3800 Elo benchmark? I'd argue that with today's technology this is unlikely, even at scale. LLMs on their own can only mimic what the training set provides; how can the student eclipse the master if it cannot truly reason? Perhaps they someday will, as the Redditor wonjaewoo noted, citing Rich Sutton's Bitter Lesson in AI research:
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin."